"ТРИЗ-Конференция - 2007" Список участников и тематика выступлений
COMPUTER-AIDED PATENT ANALYSIS:
FINDING INVENTION PECULARITIES
G. Cascini1, Italy, D. Russo1, Italy, M. Zini2, Italy
1University of Florence
Dept. of Mechanics and Industrial Technologies
Methods and Tools for Innovation Lab
2DrWolf srl
Abstract:
Today’s text mining research activities are mostly dedicated to web content mining and encompass resource discovery from the Web, document categorisation and information extraction from Web pages. The latter aims at the identification of the most relevant portion of a document and typically is based on the analysis of anchortexts, i.e. the visible part of hyperlinks. The rationale is that the larger is the number of anchortext terms in a sentence, the more relevant the sentence is likely to be since it is supposed that the relevant sentences in the destination page are related with the anchortext in the source page [1].
Nevertheless, it is clear that this kind of approach is not applicable to patent analysis, also taking into account of citation links since they are nor related to specific details of an invention.
Another typical strategy consists in building ontologies to map terms relationships in a specific field, as for example performed in [2]. Such an approach is highly time consuming, thus it is still not widely applied.
Moreover patent examiners are skeptical about the adoption of anything but Boolean search engines and manual efforts to perform prior art analyses. Nevertheless they consider a top level priority the development of means to reduce the number of document to browse [3]. It can be stated that with the same purpose of reducing human involvement, reducing the text to be read from each document is still an essential goal.
In the past the authors have developed algorithms and tools for patent analysis aimed at:
- translating the description of an invention into a conceptual functional map [4];
- identifying knowledge flows between different fields of application [5];
- investigating the properties of Small World Networks as a base for Computer-Based idea generation system [6].
Among the crucial issues that emerged during those studies, the most challenging ones are related to the identification of the relevant part of a patent, i.e. the paragraphs disclosing invention peculiarities, so that a person “skilled in the art” can focus his/her attention just on selected excerpts of the patent description, connected each other through the functional map.
In [7] regular expressions and the analysis of the detail level of the description were presented as a means to achieve such a goal.
Since then, the analysis of the detail level of the description has been further improved. In this paper the novel algorithm for detail analysis is described; then, the concept of functional subtraction is proposed: starting from the citation tree centered on the patent under analysis, the functional maps of citing and cited papers are constructed. Then common components and functions are eliminated in order to highlight invention peculiarities.
More in details, the functional analysis proposed in [4] consists in: (i) identifying the components of the invention; (ii) classifying the identified components in terms of detail/abstraction level; (iii) identifying positional and functional interactions between the components both internal and external to the system.
The components identification is performed taking into account that all the components must be referenced univocally to be identified in the patent figures.
The following step of the analysis process is dedicated to the search of descriptive locutions (i.e. sentences containing verbs like “to form”, “to constitute” etc.) and specification expressions (like “the gripper of the pivot arm”) in order to identify subsystem/supersystem relationships, hence defining a hierarchy of detail/abstraction levels.
Finally, positional and functional interactions between the identified components are determined by filtering, from the list of SAOs provided by a syntactic parser, the triads containing irrelevant verbs (i.e. verbs like “to refer”, “to show”, as well as any other verb not describing some function or action).
In Fig. 1 an exemplary view of a portion of the functional diagram extracted by the analysis of a patent is shown.
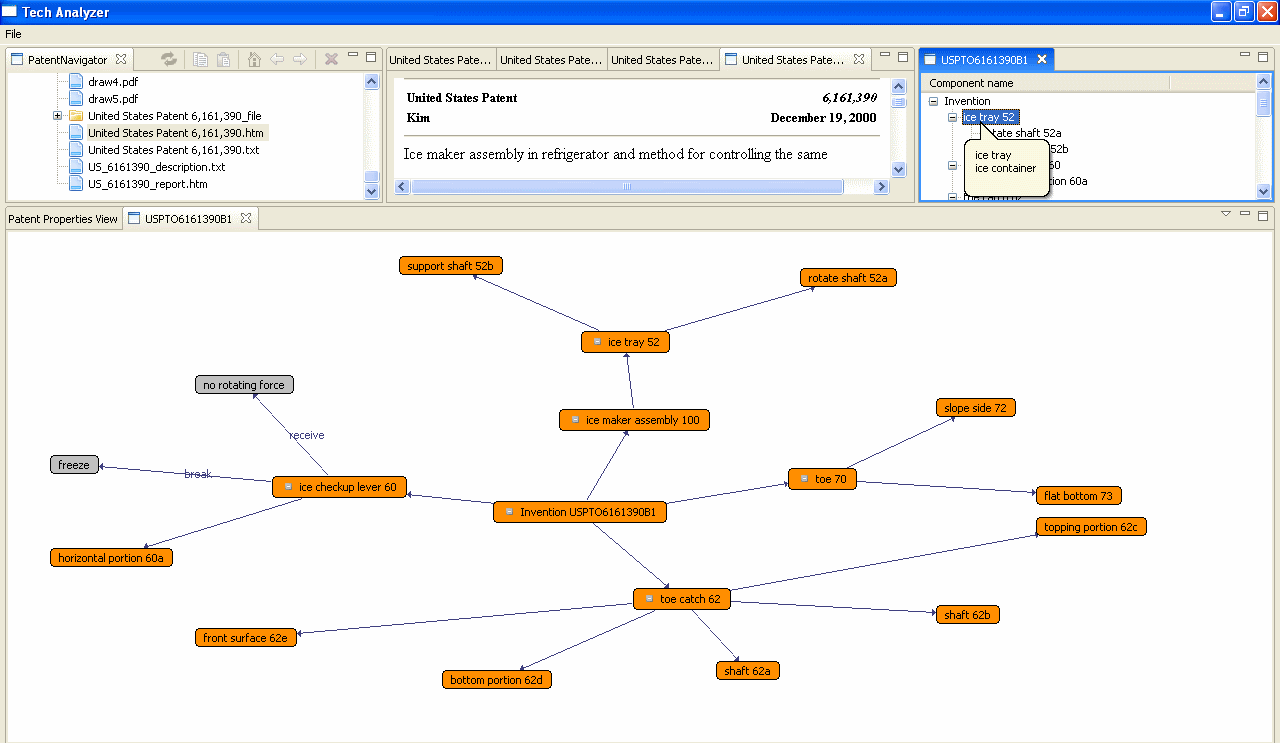
Fig. 1 – Exemplary excerpt of the functional map extracted from a patent:
US 6,161,390 – Ice maker assembly in refrigerator and method for controlling the same
It is worth to note that during the components identification phase, alternative denominations can be found for each element of the system if several multi-words are referred to the same component reference number. In the example of fig.1, “ice tray 52” is also called “ice container 52”.
Applying this analysis to a high number of patents belonging to the same IPC class provides, as a partial product of the process, an extensive list of potential synonyms (of course within the limits of the selected patent class).
As claimed above, it is useful to compare the components lists and their functional interactions extracted from patents belonging to the same citation tree. By removing from the citing patent the functional interactions recognized also in the cited patents, it is possible to focus the attention on the novelty of the invention disclosed.
Such a task is of course accomplished taking into account the previously identified synonym lists.
The full paper will start with a presentation of the scope of this research activity. Then a more comprehensive debate on the related art will be reported, taking into account what commercial tools and academic research have developed so far, as in [8, 9].
The main section will detail the proposed algorithms for analyzing the detail level of the description, for building a thesaurus and for functional subtraction and some examples will clarify how the algorithms work and what kind of results can be achieved.
Finally a discussion about strengths and weaknesses of the proposed approach and opportunities for further development will be presented.
Keywords: Patent analysis, semantic processing, syntacting parsing, functional analysis.
[1] Chen L., Chue W. L.: “Using Web structure and summarization techniques for Web content mining”, Information Processing and Management, vol. 41, 2005, pp. 1225–1242.
[2] Krauthammera M., Nenadic G.: “Term identification in the biomedical literature”, Journal of Biomedical Informatics, Volume 37, Issue 6 , December 2004, Pages 512-526.
[3] Krier M., Zaccа F.: “Automatic categorisation applications at the European patent office”, World Patent Information, Volume 24, Issue 3 , September 2002, Pages 187-196.
[4] Cascini G.: “System and Method for performing functional analyses making use of a plurality of inputs”, Patent Application 02425149.8, European Patent Office, 14.3.2002, International Publication Number WO 03/077154 A2 (18 September 2003).
[5] Cascini G., Neri F., “Natural Language Processing for patents analysis and classification”, Proceedings of the TRIZ Future 4th World Conference, Florence, 3-5 November 2004, published by Firenze University Press, ISBN 88-8453-221-3.
[6] Cascini G., Agili A., Zini M.: “Building a patents small-world network as a tool for Computer-Aided Innovation”, Proceedings of the 1st IFIP Working Conference on Computer Aided Innovation, Ulm Germany, November 14-15, 2005.
[7] Cascini G., Russo D., “Computer-Aided analysis of patents and search for TRIZ contradictions”, International Journal of Product Development, Special Issue: Creativity and Innovation Employing TRIZ, Vol. 4, Nos. 1/2, 2007.
[8] Hui B., Yub E.: “Extracting conceptual relationships from specialized documents”, Data & Knowledge Engineering, Vol. 54 (1), July 2005, Pp. 29-55.
[9] Trappey A., Hsua F. C., Trappey C. V., Linc C. I.: “Development of a patent document classification and search platform using a back-propagation network”, Expert Systems with Applications, Vol. 31 (4), November 2006, pp. 755-765.
[top]
|
